
Google Keyword Unplanner – Clickstream Data to the Rescue
Google Keyword Unplanner – Clickstream Data to the Rescue
Let’s start with the happy ending, which is actually a happy beginning, too. Moz Keyword Explorer has utilized clickstream-derived keyword data in a novel manner since day 1, allowing us to provide consistent keyword volumes despite Google Keyword Planner’s dramatic shifts in data availability and reporting. You probably haven’t noticed any changes in our keyword volume, and you probably won’t notice any going forward, which is just how we built it to begin with: resilient, evolving, and trustworthy.
That being said, the truth is that keyword data has been on shaky ground lately as the foundation upon which most keyword tools are built — Google Keyword Planner — has been grossly disrupted. This single point of failure has put a lot of tools at risk, so let me explain how we preemptively addressed this concern and subsequently haven’t lost a step.




Problem 1: Keyword Planner has started aggressively grouping keywords
You have probably seen this story floating around for quite some time. Google Keyword Planner has always combined some words, especially misspellings, so when we built Moz Explorer, we already planned out a strategy to correct for these wherever possible. It turns out that same volume disambiguation technology works for other types of grouped terms. For example, Google Keyword Planner groups “SEO” and “Search Engine Optimization” together, recognizing that one is an acronym of the other.
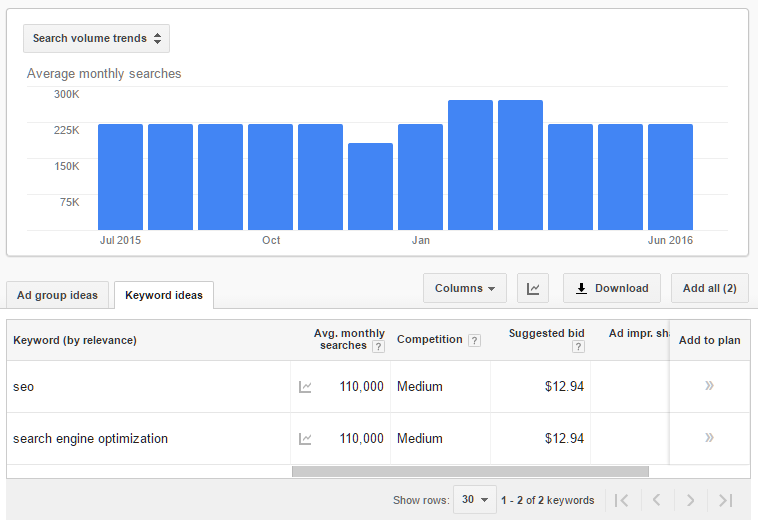 As you can see, Keyword Planner reports “SEO” and “Search Engine Optimization” as having identical average monthly searches and suggested bid price. Even worse, because Google has grouped the words when making volume predictions, but not un-grouped the words when building the graph, it appears that if you were to advertise on both of these terms, you would get over 200,000 impressions per month (at least, according to the graph). Well, you don’t have to worry about this if you’re a Moz Keyword Explorer user, because we get it right, showing the two phrases as having different volumes in the correct proportions.
As you can see, Keyword Planner reports “SEO” and “Search Engine Optimization” as having identical average monthly searches and suggested bid price. Even worse, because Google has grouped the words when making volume predictions, but not un-grouped the words when building the graph, it appears that if you were to advertise on both of these terms, you would get over 200,000 impressions per month (at least, according to the graph). Well, you don’t have to worry about this if you’re a Moz Keyword Explorer user, because we get it right, showing the two phrases as having different volumes in the correct proportions.
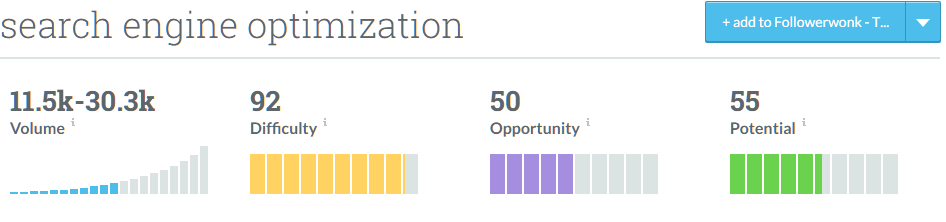
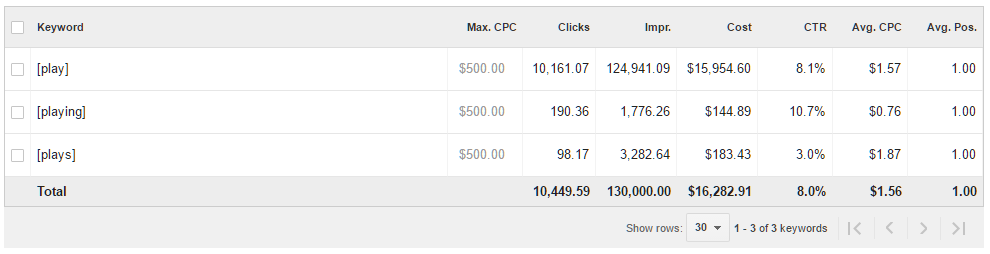
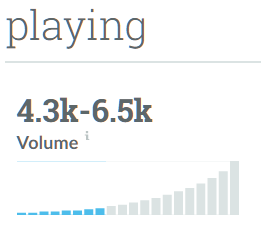
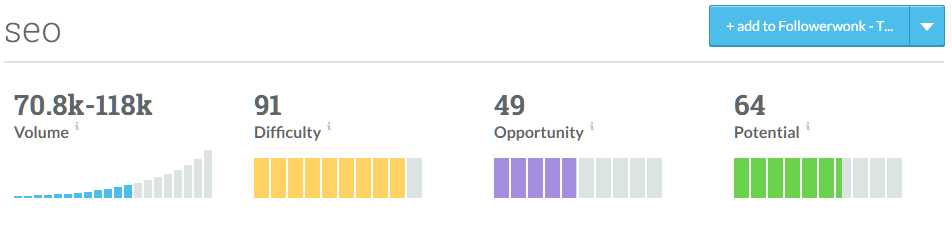 Another classic example of keyword grouping we see in Keyword Planner is related to stemming. Take, for example the word “play,” which is also the stem of “plays” and “playing.” Google groups these three terms together in Keyword Planner and presents them as having identical average monthly searches and suggested bid. Once again, we see the same graph problem as well, where it appears that someone ranking for these terms could enjoy nearly 1 million searches per month. This is actually a misrepresentation of already grouped keywords.
Another classic example of keyword grouping we see in Keyword Planner is related to stemming. Take, for example the word “play,” which is also the stem of “plays” and “playing.” Google groups these three terms together in Keyword Planner and presents them as having identical average monthly searches and suggested bid. Once again, we see the same graph problem as well, where it appears that someone ranking for these terms could enjoy nearly 1 million searches per month. This is actually a misrepresentation of already grouped keywords.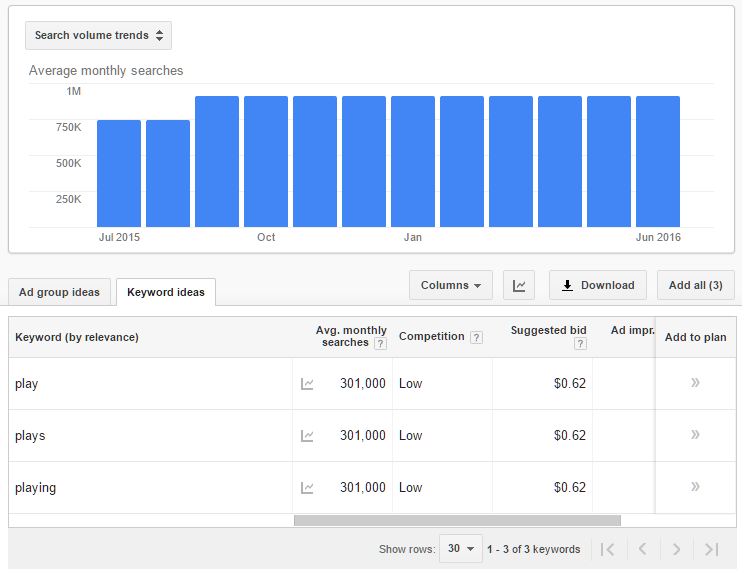
Sometimes you can get lucky and, if the keywords are commercial enough, you can see their actual proportional relationship in Keyword Forecaster. This is not always the case. Forecaster has very peculiar behavior when it perceives a grouped keyword as a misspelling rather than simply a similar term. This differing treatment of lexically vs. semantically related terms makes Forecaster an unreliable replacement for Keyword Planner alone, but in this case it serves as a decent illustration. If we were to set identical bids in Google for these terms, the keyword “play” would return far more impressions and clicks than “playing” or “plays.”
 We can confirm this with our clickstream data, which gives us similar representations. We can marry clickstream data with historical data, forecaster data, and planner data to build our own volume predictions.
We can confirm this with our clickstream data, which gives us similar representations. We can marry clickstream data with historical data, forecaster data, and planner data to build our own volume predictions.
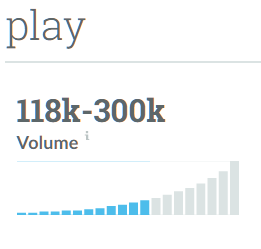
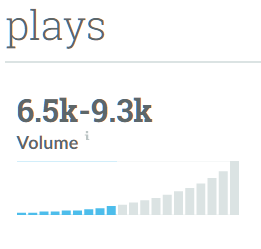
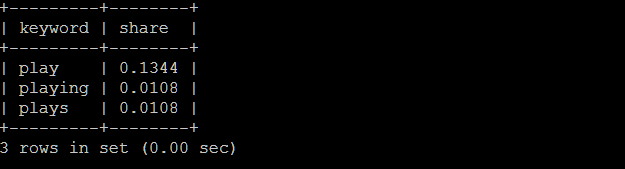 Which, when all worked out, looks something like this:
Which, when all worked out, looks something like this:
 |
 |
 |
Problem 2: Keyword Planner has started throttling access to raw data for users not running active campaigns.
In perhaps a bigger bombshell announcement, Google has started obfuscating data for users who aren’t spending enough money in Adwords. The ranges are very large and, frankly, unworkable for anyone looking to do keyword research (for Adwords or SEO). But, once again, Moz Keyword Explorer’s blended technology keeps us ahead of the curve. Even if we were never able to get keyword volume again from Google Keyword Planner, we would be able to continue to provide users with a stable set of volume metrics that models closely to actual Google search volume.
How we do it:
1. How do we determine when words are grouped together?
This is one place where size really does matter. Moz has a huge keyword corpus of over 2 billion keywords, and we have collected volume from Google for hundreds of millions of them. Because of this, we can identify the rare occasions where two words have identical search data histories (same CPC, competition, volume, etc.). Sometimes two words share the same history just by chance, so we then use a variety of NLP and string-similarity measurements, including an incredible deep learning model built by Dr. Matt Peters to determine if the keywords are related to one another. It is important to use multiple methods because string-similarity methods are notoriously finicky. Once we apply these various string similarity metrics to the set of keywords with identical metrics, we can identify those that are grouped by Keyword Planner.
2. Once we know what words are grouped together, how do we determine the volume of each?
Once we have a group of related terms, we apply a predictive model based on data both from Google and our clickstream sources to determine the appropriate percentage of traffic that should be allocated to each word or phrase. Again, this is where having a huge data set really shines. Without detailed data on the constituent phrases, we would have to make unjustified assumptions about how to divide the grouped volume. Luckily, this is rarely the case, and we choose to be explicit with our customers and state “no data” when we do not have sufficient data to make a prediction.
3. How do we determine the volume for keywords when we don’t have Google Keyword Planner data?
Luckily, we can rely on our vast clickstream data to make these calculations. Clickstream data is intrinsically noisy and biased, so our models are quite comprehensive to remove random occurrences, strip out bias in the sampled data, and model projected traffic against the general Google corpus. There is a chicken/egg problem here, to a degree, because we can’t model against the Google data if it has grouped-keyword problems, but we can’t solve all the grouped keyword problems without the clickstream data. However, as long as we are reasonably certain that the clickstream data is internally proportional, then we can rely on it to solve the grouping problem first, and then use the ungrouped Keyword Planner data to model against with general clickstream data. It is a complex procedure, but in the end we can reasonably predict monthly search volume without ever having data from Google.
Let me give you an example. Khizr Khan, father of Purple Heart recipient Captain Humayun Khan, has caused quite a political stir following his speech at the DNC convention. His story represents a common issue in keyword data in that, prior to his speech, no one ever searched his name. After his speech, his name shot up on Google Trends but, even then, Google Keyword Planner has lagged in reporting his numbers due to the month-long delays in releasing data. Because our clickstream data can pick up on rising trends, we can predict Google volume without needing to have Google Keyword Planner data.
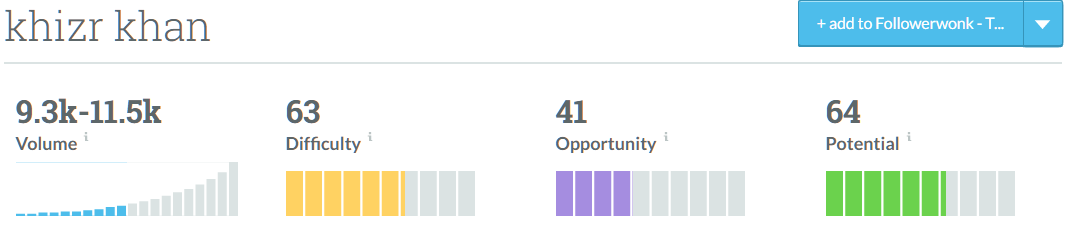
This is also the case for keywords that are not trending. If we see a term that is regularly searched in our clickstream data, but is not represented in our Google data set, we can make predictions without having to rely on the potentially misleading (grouped volumes) or inaccessible data sources that Google Keyword Planner has become.



